1 入门
1.1 模块概述
在本模块中,您将了解:
什么是图数据建模。
领域知识对建模的重要性。
图数据模型和实例模型之间的区别。
1.2 什么是图数据建模?
为什么要建模?
如果您要使用 Neo4j 图来支持部分或全部应用程序,则必须与利益相关者协作设计一个图形,该图形将:
回答应用程序的关键用例。
为关键用例提供最佳的 Cypher 语句属性。
Neo4j 图的组件
用于定义图形数据模型的Neo4j组件包括:
节点 Nodes
标签 Labels
关系 Relationships
属性 Properties
数据建模过程
以下是创建图形数据模型的步骤:
了解领域并为应用程序定义特定用例(问题)。
开发初始图形数据模型:
对节点(实体) 进行建模。
对节点之间的关系进行建模。
针对初始数据模型测试用例。
使用 Cypher 创建包含测试数据的图形(实例模型)。
测试用例,包括针对图形的属性。
由于关键用例的更改或性能原因,重构(改进)图形数据模型。
在图上实现重构并使用 Cypher 重新测试。
图形数据建模是一个迭代过程。您的初始图形数据模型是一个起点,但随着您对用例的更多信息或用例发生变化,初始图形数据模型将需要更改。此外,您可能会发现,尤其是在图形缩放时,您需要修改图形(重构)以实现关键用例的最佳性能。
重构在开发过程中非常普遍。Neo4j图有一个非常灵活的可选模式,这与RDBMS中的模式不同。Cypher 开发人员可以轻松修改图形以表示改进的数据模型。
1.3 领域
了解应用程序的领域
在开始数据建模过程之前,您必须:
确定应用程序的利益干系人和开发人员。
与利益相关者和开发人员:
详细描述应用程序。
确定应用程序的用户(人员、系统)。
就应用程序的用例达成一致。
对用例的重要性进行排名。
电影领域
在Neo4j Fundamentals课程中,您被介绍给一个“入门”电影图谱。
该领域包括电影、演员或导演以及为电影评分的用户。使这个领域变得有趣的是图中节点之间的连接或关系。
使用案例
应用程序的大多数用例都可以通过一个完整的问题列表来枚举。这些用例有助于定义应用程序在运行时的行为方式。
以下是您将使用来开发初始图形数据模型的用例:
人们在电影中演了什么?
哪个人导演了一部电影?
一个人演了什么电影?
有多少用户对一部电影进行了评分?
谁是演电影的最年轻的人?
一个人在电影中扮演了什么角色?
根据互联网电影数据库的数据,特定年份评分最高的电影是什么?
演员演过什么电影?
哪些用户给电影的评分为5?
在我们的领域中,我们希望将出演或导演过电影的人与为电影评分的用户或评论者区分开来。我们有更多关于人们的信息,例如他们的出生日期,他们的tmdbId等。对电影进行评级的用户只会被命名或识别。
1.4 模型的用途
模型类型
为应用程序执行图形数据建模过程时,至少需要两种类型的模型:
数据模型
实例模型
数据模型
数据模型描述图形的标签、关系和属性。它没有将在图形中创建的特定数据。
下面是一个数据模型示例:

没有任何东西可以唯一标识具有给定标签的节点。但是,图形数据模型很重要,因为它定义了在应用程序创建和使用图形时将用于标签、关系类型和属性的名称。
建模的规范指南
在开始图形数据建模过程时,请务必就标签、关系类型和属性键的命名方式达成一致。标签、关系类型和属性键区分大小写,这与不区分大小写的 Cypher 关键字不同。
Neo4j的最佳实践是在命名图形元素时使用以下方法,但您可以自由地为您的应用程序使用任何约定。
标签是以大写字母开头的单个标识符,可以是驼峰大小写。CamelCase.
- 示例:Person、Company、GitHubRepo
关系类型是所有大写字母中带有下划线字符的单个标识符。
- 示例:FOLLOWS、MARRIED_TO
节点或关系的属性键是单个标识符,它以小写字母开头, 可以是驼峰大小写。CamelCase.
- 示例:deptId、firstName
注: 属性键名称不必是唯一的。例如,“Person”节点和“Movie”_节点,每个节点都可以具有 tmdbId 的属性键。
实例模型
图形数据建模过程的一个重要部分是针对用例测试模型。为此,您需要有一组示例数据,您可以使用这些数据来查看是否可以用模型来回答用例。
下面是一个实例模型的示例:
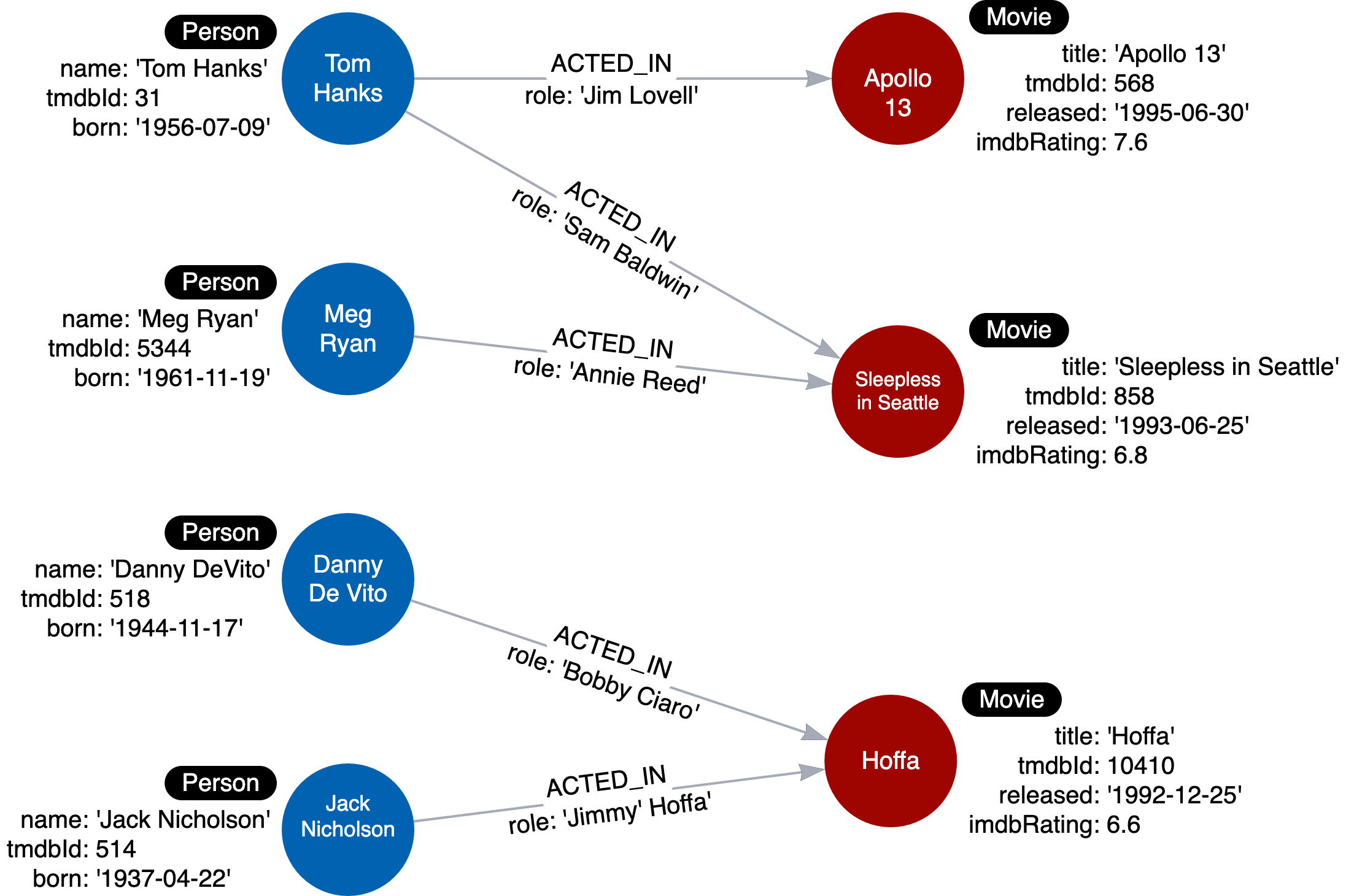
在此实例模型中,我们创建了“Person”和“Movie”节点的一些实例及其关系。拥有这种类型的实例模型将有助于用于测试我们的用例。
2 节点建模
2.1 模块概述
在本模块中,您将了解:
从您的使用案例中识别实体。
在图形中创建节点以支持数据模型。
2.2 建模节点
定义标签
实体是应用程序用例中的主要名词:
食谱中使用了哪些成分?
谁嫁给了这个人?
您的用例的实体将是图形数据模型中标记的节点。
在 Movie 域中,我们在用例中使用名词来定义标签,例如:
人们在电影中演了什么?
哪个人导演了一部电影?
一个人演了什么电影?
以下是我们将开始使用的一些标记节点。

请注意,这里我们使用 CamelCase 作为标签的名称。
节点属性
节点属性用于:
唯一标识节点。
回答应用程序用例的具体细节。
返回数据。
例如,在 Cypher 语句中,属性用于:
锚点(开始查询的位置)。
MATCH (p:Person {name: 'Tom Hanks'})-[:ACTED_IN]-(m:Movie) RETURN m
遍历图形(导航)。
MATCH (p:Person)-[:ACTED_IN]-(m:Movie {title: 'Apollo 13'})-[:RATED]-(u:User) RETURN p,u
从查询返回数据。
MATCH (p:Person {name: 'Tom Hanks'})-[:ACTED_IN]-(m:Movie) RETURN m.title, m.released
“影片”图表中的唯一标识符
在 Movie 图中,我们使用以下属性来唯一标识节点:
Person.tmdbId
Movie.tmdbId
节点的属性
除了用于唯一标识节点的 tmdbId 之外,我们还必须重新访问用例以确定节点必须保存的数据类型。
以下是我们将重点介绍的特定于 _“人物”和“电影”_节点的用例列表。这些用例告诉我们_电影_和_人物_节点中所需的数据。
| 用例 | 所需步骤 |
|---|---|
| 1:电影中有哪些人演戏?
What people acted in a movie? | 1. 按title检索电影。
2. 返回参与者的names。 |
| 2:哪个人导演了一部电影?
What person directed a movie? | 1. 按title检索电影。
2. 返回导演的name。 |
| 3: 一个人演了什么电影?
What movies did a person act in? | 1. 按name检索人员 **。**
2. 返回影片的**titles **。 |
| 5: 谁是演电影的最年轻的人?
Who was the youngest person to act in a movie? | 1. 按title检索电影。
2. 评估演员的ages。
3. 返回参与者的name。 |
| 7: 根据imDB的数据,特定年份评分最高的电影是什么?
What is the highest rated movie in a particular year according to imDB? | 1. 检索特定年份released的所有电影。
2. 评估imDB ratings。
3. 返回影片title。 |
| 8: 演员演了什么剧情片?
What drama movies did an actor act in? | 1. 按name检索参与者。
2. 评估演员所演电影的genres。
3. 返回影片titles。 |
鉴于这些用例的步骤的详细信息,以下是我们将为 Movie 节点定义的属性:
电影标题(字符串)Movie.title (string)
电影发行(日期)Movie.released (date)
电影评级(0-10之间的小数)Movie.imdbRating (decimal between 0-10)
电影流派(字符串列表)Movie.genres (list of strings)
以下是我们将为 Person 节点定义的属性:
Person.name(string)
Person.born (date)
Person.died (date)
注意:_died_的属性将是可选的。
下面是初始数据模型:

下面是您将要创建的初始实例模型:
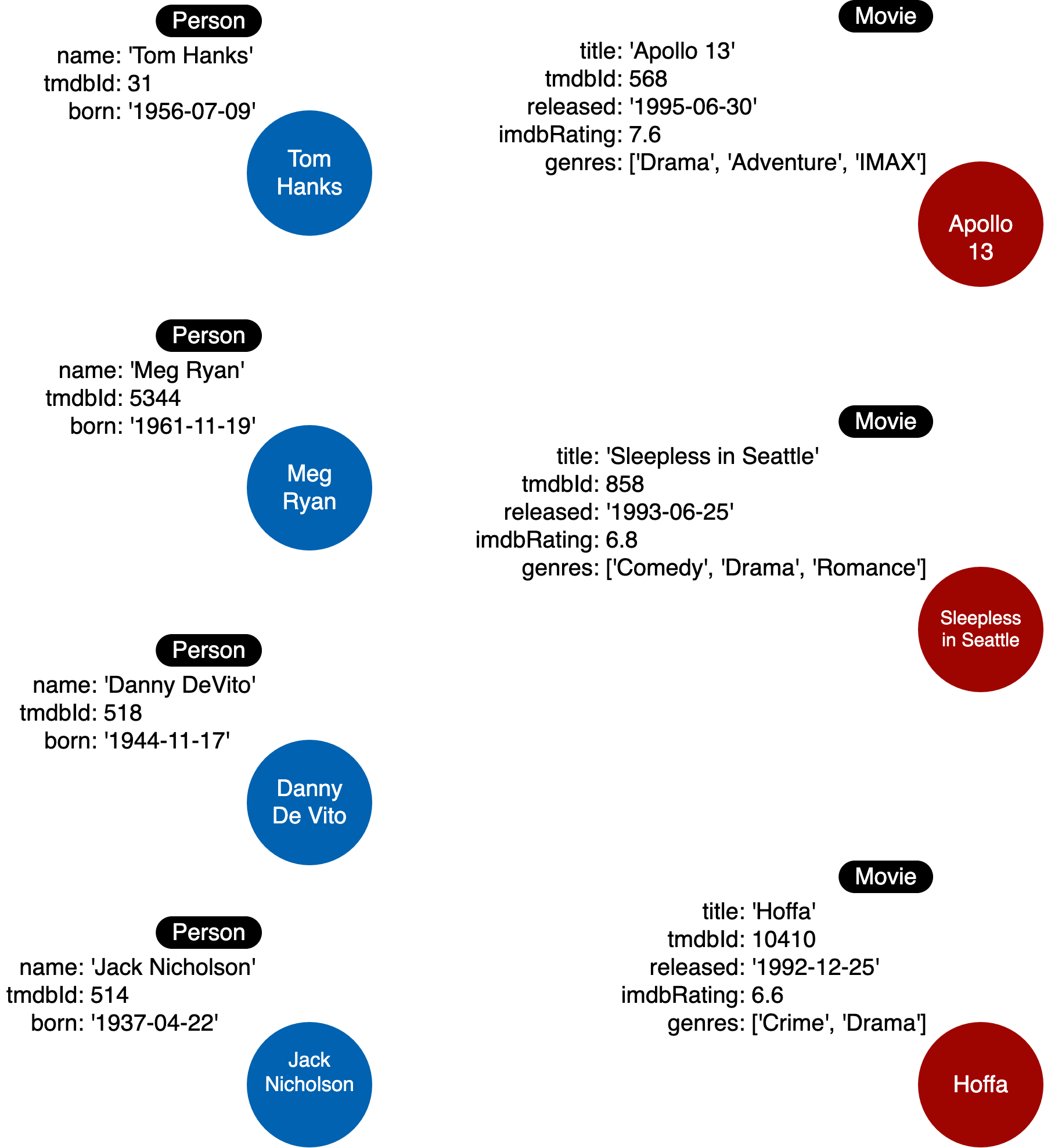
2.3 创建节点
这里在网页的右侧直接可以输入cypher语句进行尝试
以下是您将要使用的初始实例模型:
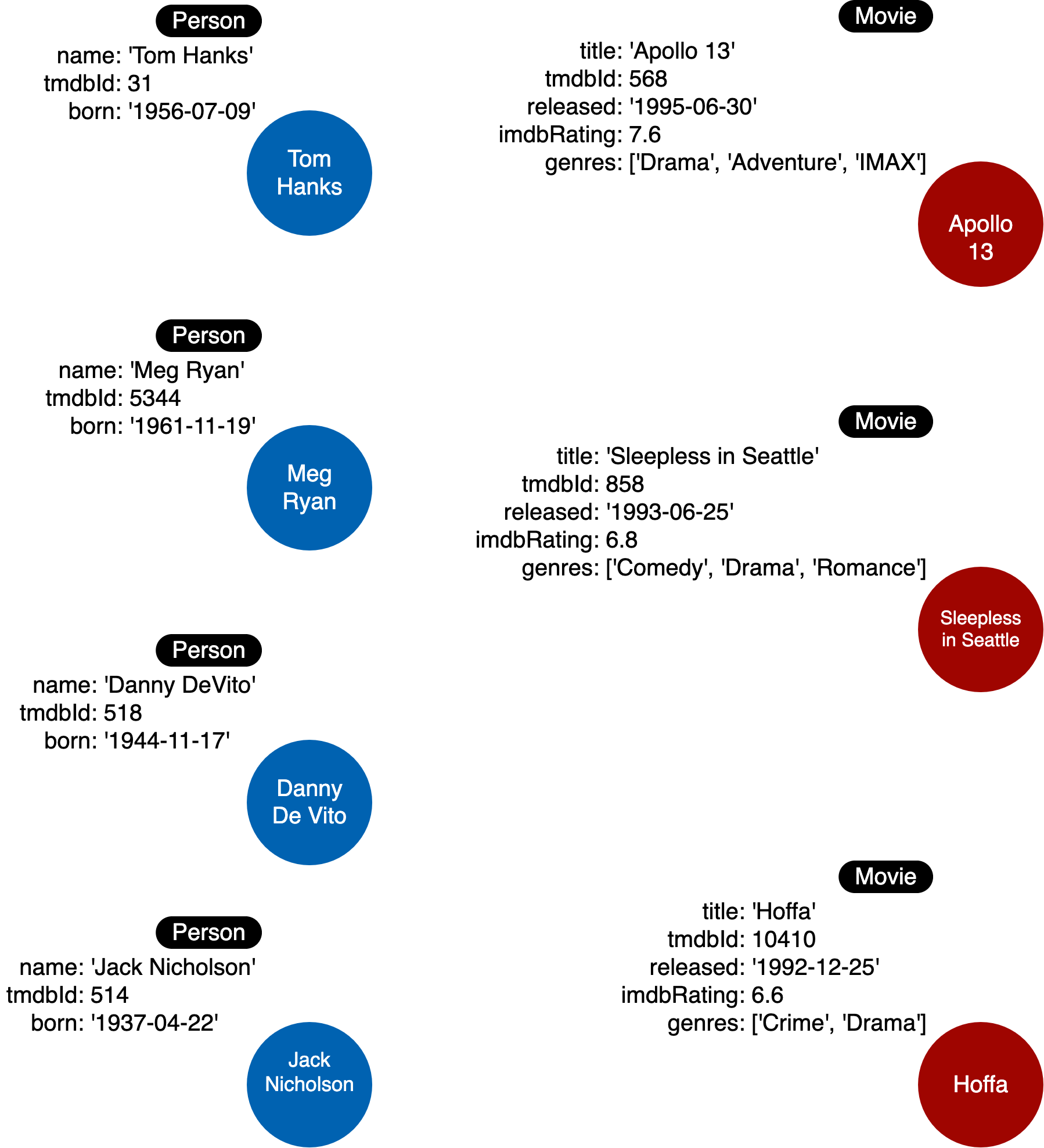
运行下面的 Cypher 代码,将“人物”和“电影”节点添加到图形中,这将用作我们的初始实例模型:
运行查询。
MATCH (n) DETACH DELETE n;
MERGE (:Movie {title: 'Apollo 13', tmdbId: 568, released: '1995-06-30', imdbRating: 7.6, genres: ['Drama', 'Adventure', 'IMAX']})
MERGE (:Person {name: 'Tom Hanks', tmdbId: 31, born: '1956-07-09'})
MERGE (:Person {name: 'Meg Ryan', tmdbId: 5344, born: '1961-11-19'})
MERGE (:Person {name: 'Danny DeVito', tmdbId: 518, born: '1944-11-17'})
MERGE (:Person {name: 'Jack Nicholson', tmdbId: 514, born: '1937-04-22'})
MERGE (:Movie {title: 'Sleepless in Seattle', tmdbId: 858, released: '1993-06-25', imdbRating: 6.8, genres: ['Comedy', 'Drama', 'Romance']})
MERGE (:Movie {title: 'Hoffa', tmdbId: 10410, released: '1992-12-25', imdbRating: 6.6, genres: ['Crime', 'Drama']})
注意,在此代码中,我们使用 Neo4j 最佳实践指南来命名标签 (CamelCase) 和属性(camelCase)。
您可以通过运行以下代码来验证是否已创建节点:
MATCH (n) RETURN n
共有 7 个节点。
2.4 标识新标签
我们需要为一个新的用例重构模型:
用例#4:有多少用户对一部电影进行了评分?
我们已经为我们的用例确定了 _“人物”和“电影”_节点:
What people acted in a movie?
What person directed a movie?
What movies did a person act in?
以下是我们当前的图形数据模型:

我们还有一个必须建模的附加用例。我们需要能够将评级网站用户与其他类型的演员和导演区分开来。
注意:在学习本课程时,您可以使用任何想要的技术来绘制图形数据模型。大多数人只使用笔和纸。
测验:向模型添加新标签
应向节点添加什么标签以标识已对电影进行评分的任何用户?
What label should be added to nodes to identify any Users who have rated a movie?
提示
我们正在寻找一个字符串,该字符串定义了一个标签,可用于查找代表我们数据库中用户的任何节点。
我们已经定义了 “电影” 和“人物”标签。我们希望将电影评分的网站用户与出演或导演过电影的用户区分开来。
另请注意,在本课程中,我们将使用CamelCase作为标签名称的标准。也就是说,标签将以大写字母开头。
答案是: User
在本次挑战中,您展示了为图形数据模型识别附加标签的技能。
在下一个挑战中,您将演示如何在图中创建具有新标签和属性的节点。
2.5 创建更多节点
我们想在图中添加几个用户节点,以便我们可以测试对模型的更改。
任何User节点都将具有以下属性:
userId - an integer (eg.
123)name - a string (eg.
User’s Name)
创建两个用户节点:
‘Sandy Jones’ with the userId of 534
‘Clinton Spencer’ with the userId of 105
MERGE (u:User {userId: 123})
SET u.name = "User's Name"
修改 Sandbox 窗口中的 MERGE 语句以在数据库中查找或创建两个用户。
您可以在一个查询中创建两个节点,也可以在两个单独的查询中创建节点。
MERGE (u:User {userId: 534})
SET u.name = 'Sandy Jones'
MERGE (m:User {userId: 105})
SET m.name = 'Clinton Spencer'
在这个挑战中,您展示了您可以创建一些节点来支持您的实例模型。
您的实例模型现在应该如下所示:
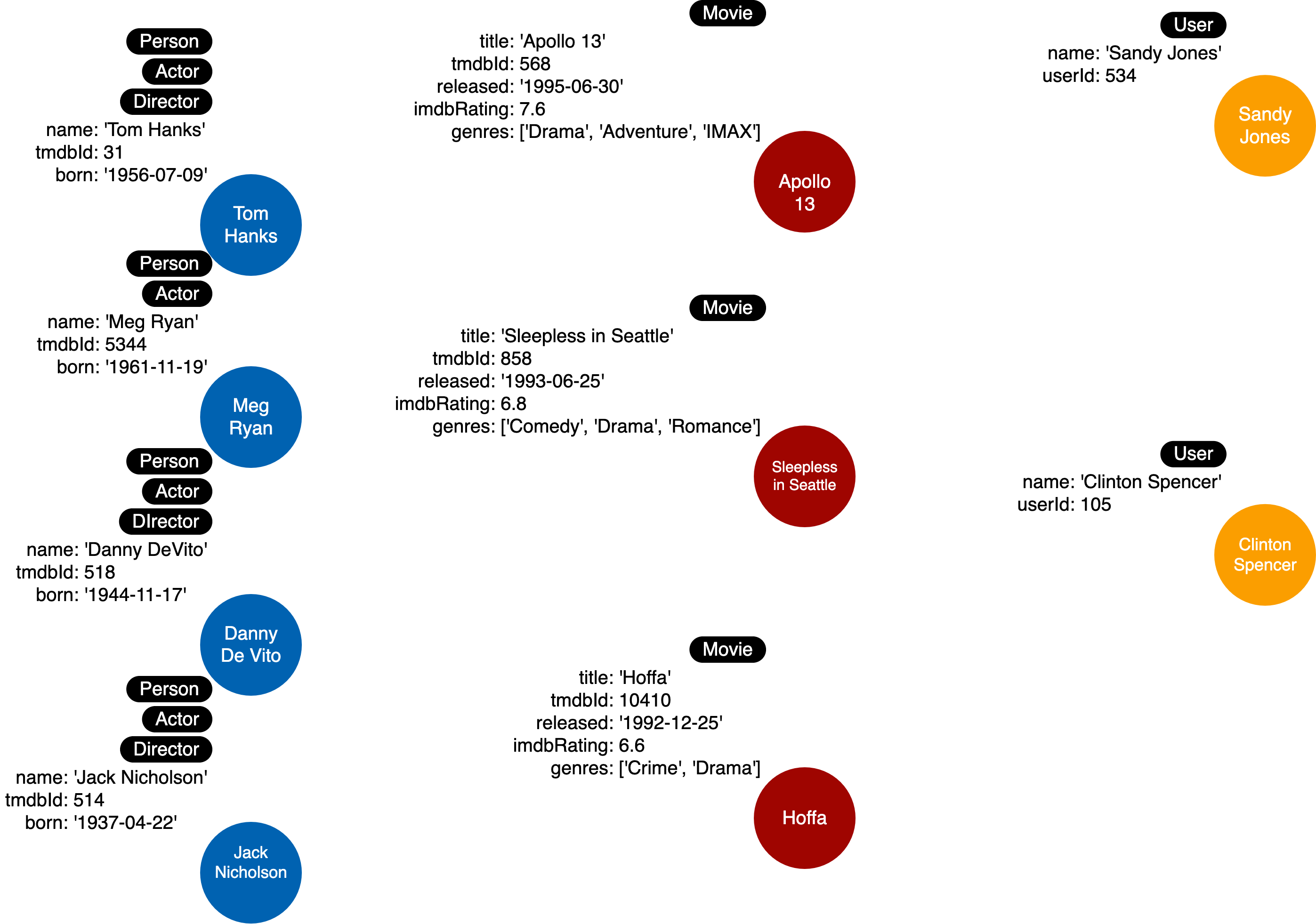
在下一个模块中,您将学习如何向模型添加关系。
3 关系建模
3.1模块概述
在本模块中,您将了解:
从您的使用案例中识别关系。
在关系图中创建关系以支持数据模型。
3.2建模关系
关系是实体之间的连接
连接是您的用例中的动词:
食谱中使用了哪些成分?
谁嫁给了这个人?
乍一看,连接很简单,但它们的微观和宏观设计可以说是图形性能中最关键的因素。使用“连接是动词”是入门的一个很好的速记,但在本课程的后面部分,您将了解其他重要的注意事项。
命名关系
为图形中的关系选择好的名称(类型)非常重要。关系类型需要对利益干系人和开发人员都直观。关系类型不能与实体名称混淆。
因此,在我们的示例用例中,我们可以定义以下关系类型:
使用
已婚
请注意,我们使用Neo4j最佳实践,所有大写字母/下划线字符作为关系的名称。
关系方向
在 Neo4j 中创建关系时,必须显式指定方向,或者通过指定模式中的从左到右的方向推断方向。在运行时,在查询期间,通常不需要方向。
在上面显示的示例用例中,必须创建 USES 关系才能从 Recipe 节点转到 Ingredient 节点。

可以创建已婚关系以从任一节点开始,因为这种类型的关系是对称的。

关系通常介于 2 个不同的节点之间,但也可以是同一节点。
展开

在这里,我们有实体(个人,住所)表示不是单个节点,而是网络或链接节点。
这是扇出的一个极端例子,对于任何现实生活中的解决方案来说,几乎肯定是过分的,但是一定程度的扇出可能非常有用。
例如,将姓氏拆分到单独的节点上有助于回答“谁的姓氏为 Scott?”这个问题。同样,将城市作为单独的节点有助于解决“谁与帕特里克·斯科特住在同一个城市?”的问题。
扇出的主要风险是它可能导致非常密集的节点或超级节点。这些是具有数十万个传入或传出关系的节点,超级节点需要仔细处理。
“影片”图形中的关系
现在,让我们看一下如何识别这些用例的关系:
人们在电影中演了什么?
哪个人导演了一部电影?
一个人演了什么电影?
给定这些用例,我们将关系命名为:
ACTED_IN
指示
此外,这两种关系类型都从 _“人”节点开始,到“影片”_节点结束。
以下是支持的图形数据模型:

下面是支持此图形数据模型的实例模型:
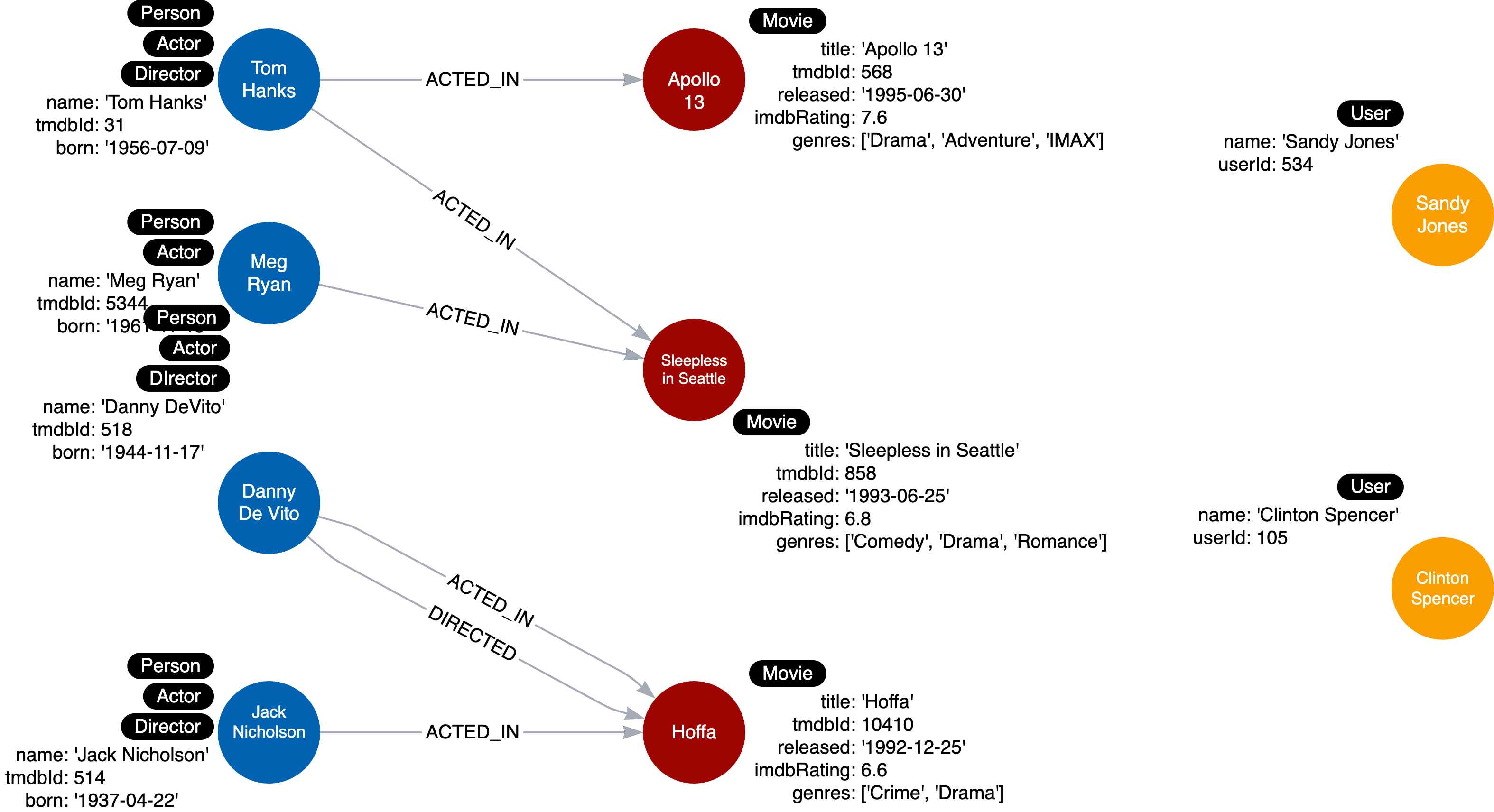
汤姆·汉克斯出演了两部电影。梅格·瑞安(Meg Ryan)和杰克·尼科尔森(Jack Nicholson)各自出演了一部电影。丹尼·德维托(Danny DeVito)都出演并执导了同一部电影。通过探索与此实例模型的关系,我们看到电影阿波罗 13 号在图中只有一个演员,但另外两部电影各有两个演员。
关系的属性
关系的属性用于丰富两个节点之间的关系。当您为关系定义属性时,这是因为您的用例会询问有关两个节点如何相关的特定问题,而不仅仅是它们是否相关。
例如,我们在_Neo4j基础_课程中看到,可以将属性添加到关系中以进一步描述它。
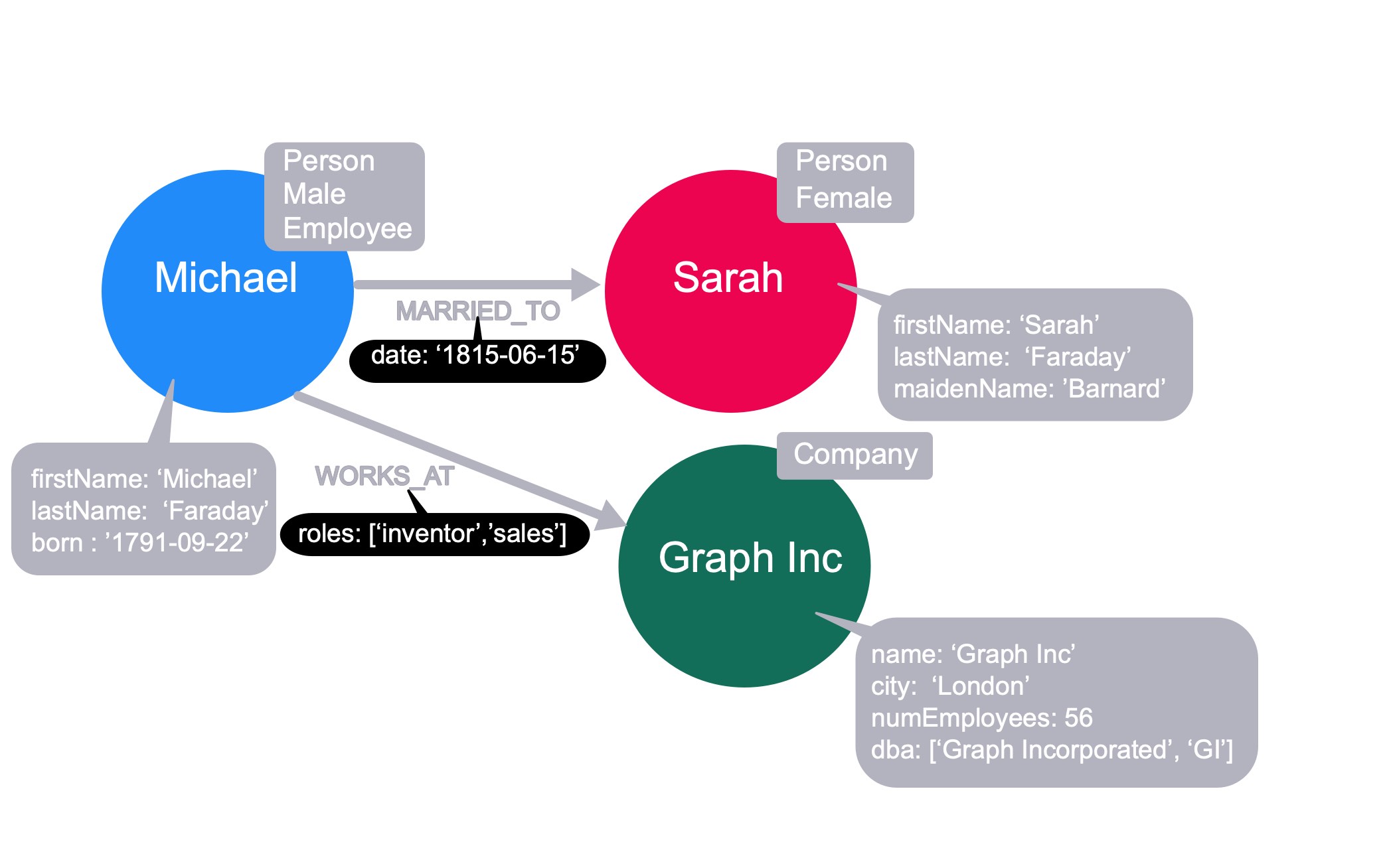
在这里,我们看到我们在_已婚_关系上有一个_日期_属性,以进一步描述迈克尔和莎拉之间的关系。此外,我们在_WORKS_AT_关系上有一个_角色_属性,用于描述 Michael 在 Graph Inc. 工作时拥有或拥有的角色。
这些属性特定于两个节点之间的关系。
影片图表中的关系属性
就像您分析命名标签、关系类型和节点属性的用例一样,您可以使用这些用例来提出关系的属性。
下面是一个用例:
- 一个人在电影中扮演了什么角色?
此用例的运行时操作包括:
检索人员的姓名。
遵循与电影ACTED_IN关系。
按标题筛选影片。
从两个节点之间的ACTED_IN关系返回角色。
我们知道,对于此用例,特定_ACTED_IN_关系_的角色_是必需的。因此,我们将_角色_属性添加到此关系中。下面是数据模型:
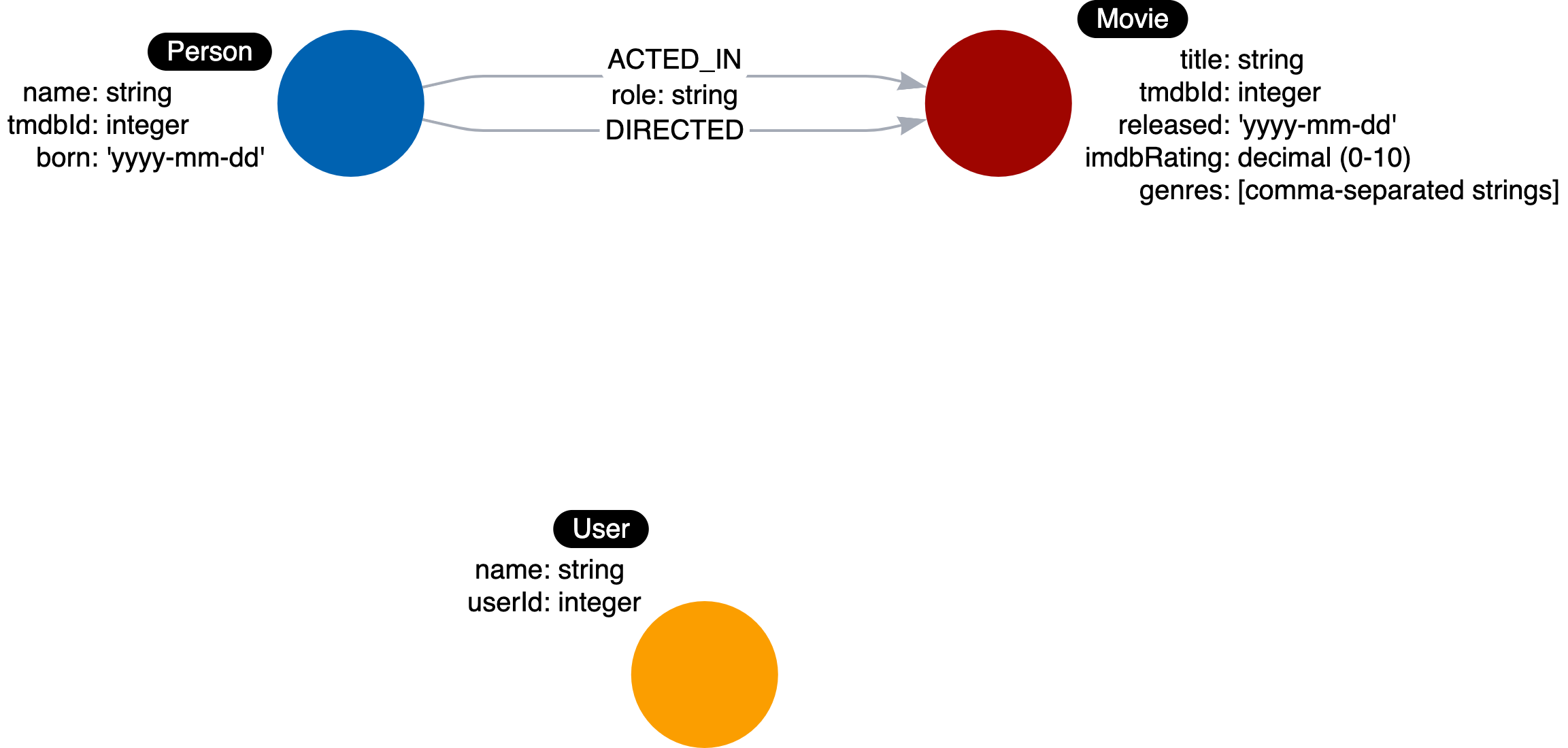
下面是您将要创建的实例模型:
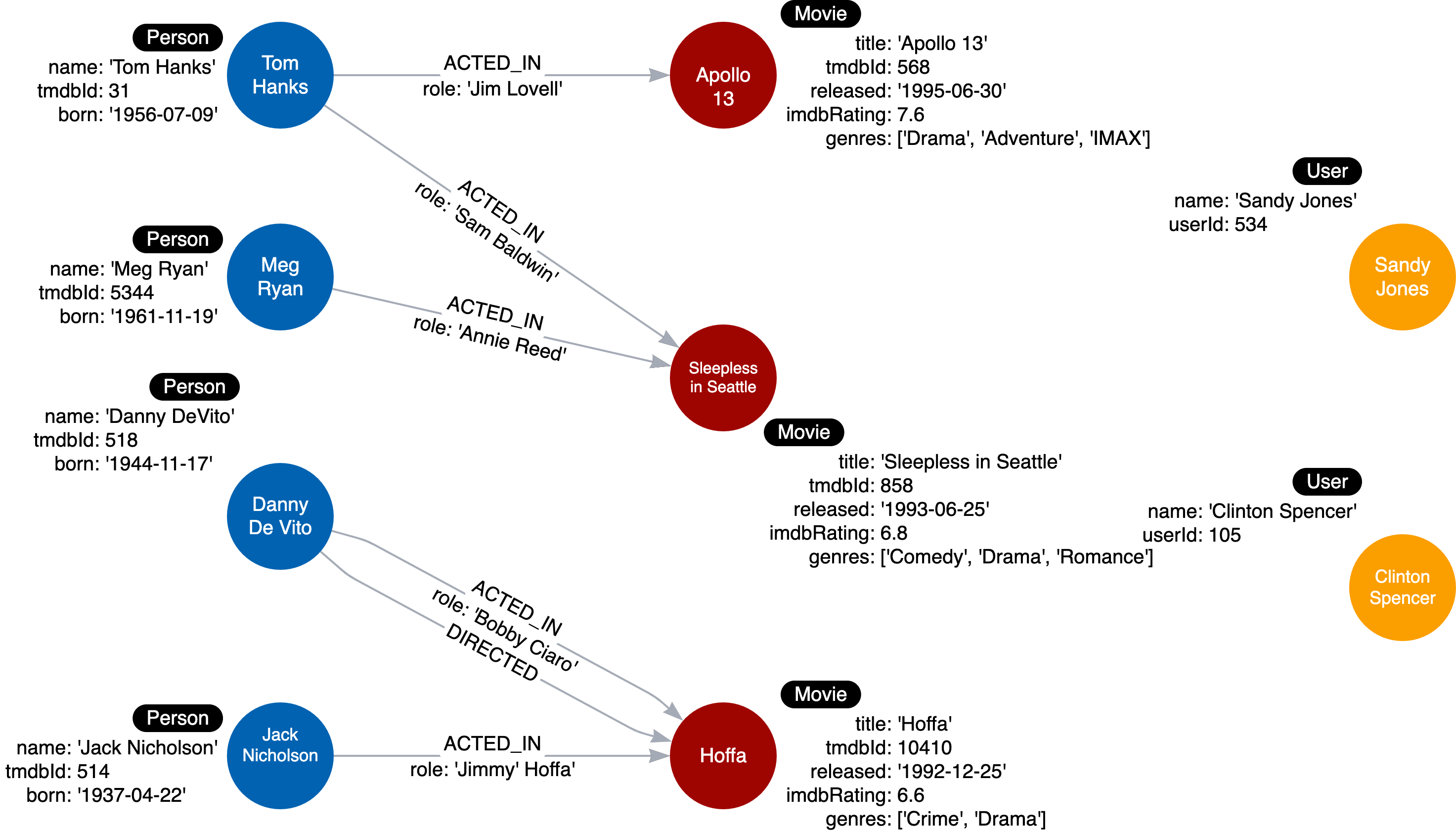
此处的每个_ACTED_IN_关系对_角色_属性都有不同的值。



